
Your Garmin Is Collecting Data You’ll Never Read. Here’s How to Fix That
I ride with a Garmin Fenix 8, an Edge 1050, Rally power meter pedals, a cadence sensor, speed sensor, DI2 integration, a rear radar, and a heart rate monitor. The…

I'm a technologist based in Denver, Colorado, obsessed with tinkering. When I'm not with my family or getting outdoors, you'll find me in my homelab experimenting with GPU clusters for LLM inference, optimizing Kubernetes deployments, or testing CNCF projects to see which ones actually deliver. I'm a Senior Engineering Manager of Foundation at Strava, and I've spent the last decade helping fast-growth startups navigate technical challenges at scale. I write here about what I'm actually building: AWS cost optimization that drives 40%+ savings, AI/ML infrastructure in production, cloud architecture patterns that work under pressure, and the real experience of working with emerging technologies (not the conference talk version). I consult on cloud infrastructure, AI implementation, and Kubernetes management for companies that need systems to work reliably at scale.
I ride with a Garmin Fenix 8, an Edge 1050, Rally power meter pedals, a cadence sensor, speed sensor, DI2 integration, a rear radar, and a heart rate monitor. The…
If you’re a CTO or engineering lead making framework decisions in 2025, you’re probably evaluating based on familiar criteria: performance, ecosystem maturity, team expertise, hiring pool. Those still matter. But…
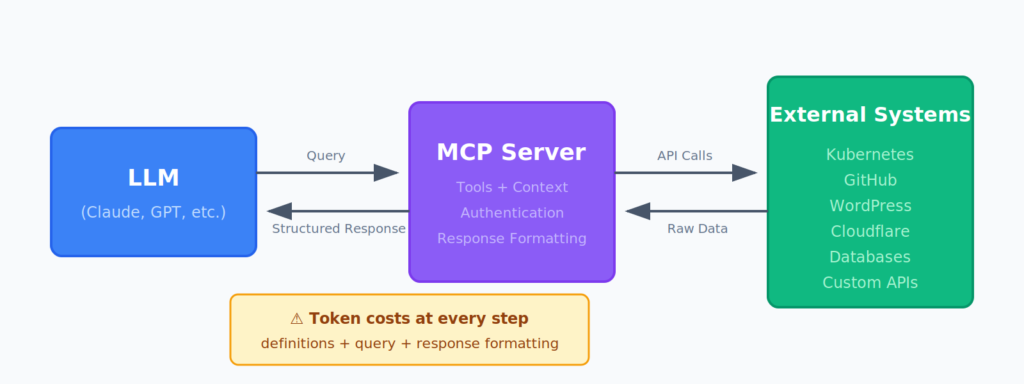
My four-year-old learned to use a shape sorter yesterday. Watching her figure it out reminded me of my experience with MCP servers over the last six months. Not because the…